
DHistory
FanOut을 활용하여 NewsFeed Performance 향상 본문
개요
SNS NewsFeed 조회 시 팔로잉 유저들의 최신 게시글을 조회해야합니다.
팔로잉한 유저의 수가 1800명이고 각 유저들이 1000개씩 글을 작성했다고 가정합니다.
게시글의 전체 데이터 개수는 1,800,000 건입니다.

팔로잉한 유저들의 게시글 중 최근 100개의 게시글을 조회를 진행해보겠습니다.
일반 쿼리 조회 구현 시

피드 목록 조회 시 비용이 비싼 쿼리를 조회해야합니다.
(Post의 Dummy Data를 대규모 데이터로 넣기 위해선 시간이 오래 걸리므로 비싼 쿼리로 만들어 진행)
@Service
@RequiredArgsConstructor
public class FeedService {
private final PostRepository postRepository;
private final RedisClient redisClient;
@Transactional(readOnly = true)
public List<FeedResponse> getNewsFeed(Long accountId) {
List<Post> posts = postRepository.getNewsFeed(accountId);
return posts.stream()
.map(post -> new FeedResponse(post.getId(), post.getTitle(), post.getContents()))
.toList();
}
}@Repository
public class PostRepository {
private final JPAQueryFactory jpaQueryFactory;
public PostRepository(JPAQueryFactory jpaQueryFactory) {
this.jpaQueryFactory = jpaQueryFactory;
}
public List<Post> getNewsFeed(Long accountId) {
return jpaQueryFactory.select(post)
.from(post)
.join(follow).on(post.account.id.eq(follow.following.id))
.where(follow.follower.id.eq(accountId))
.orderBy(post.createdAt.desc())
.limit(1000)
.fetch();
}
}
팔로우한 유저도 늘어나고 게시글 수도 늘어나게 된다면 쿼리 시간이 증가하기 때문에 Latency는 자연스레 늘어납니다.
그 결과 유저는 NewsFeed 조회 시 1분 이상 대기를 해야합니다.

Q) 매 번 비싼 쿼리를 수행하지 않고 NewsFeed 조회를 진행할 수 있는 방법을 무엇이 있을까요?
A) 최근 조회한 NewsFeed의 Post ID를 Redis에 저장한다면 비용이 높은 쿼리를 수행하지 않고 최신 NewsFeed를 여러 번 조회할 수 있습니다.
Redis를 사용하여 NewsFeed 목록 캐싱

사용자의 정보를 Key로 설정하고 NewsFeed의 정보를 Value로 설정합니다.
이 후 NewsFeed 조회 시 다음과 같은 동작을 수행합니다.
1. 사용자에 해당하는 Redis 데이터 조회
2. Redis 데이터가 없는 경우 DB 조회 및 Redis 저장
@Service
@RequiredArgsConstructor
public class FeedService {
private static final String POST_KEY = "account:%d:posts";
private final PostJpaRepository postJpaRepository;
private final PostRepository postRepository;
private final AccountRepository accountRepository;
private final RedisClient redisClient;
@Transactional(readOnly = true)
public List<FeedResponse> getNewsFeed(Long accountId) {
Account account = accountRepository.findById(accountId)
.orElseThrow(() -> new NotFoundAccountException(accountId));
List<Post> posts = getPosts(account);
return posts.stream()
.map(post -> new FeedResponse(post.getId(), post.getTitle(), post.getContents()))
.toList();
}
private List<Post> getPosts(Account account) {
Long accountId = account.getId();
List<Long> postIds = redisClient.getList(POST_KEY.formatted(accountId));
if (postIds.isEmpty()) {
List<Post> posts = postRepository.getNewsFeed(accountId);
redisClient.setList(POST_KEY.formatted(account.getId()), posts.stream()
.sorted(Comparator.comparing(Post::getId))
.map(Post::getId)
.toList());
return posts;
} else {
return postJpaRepository.findAllByIdInOrderByCreatedAtDesc(postIds);
}
}
}

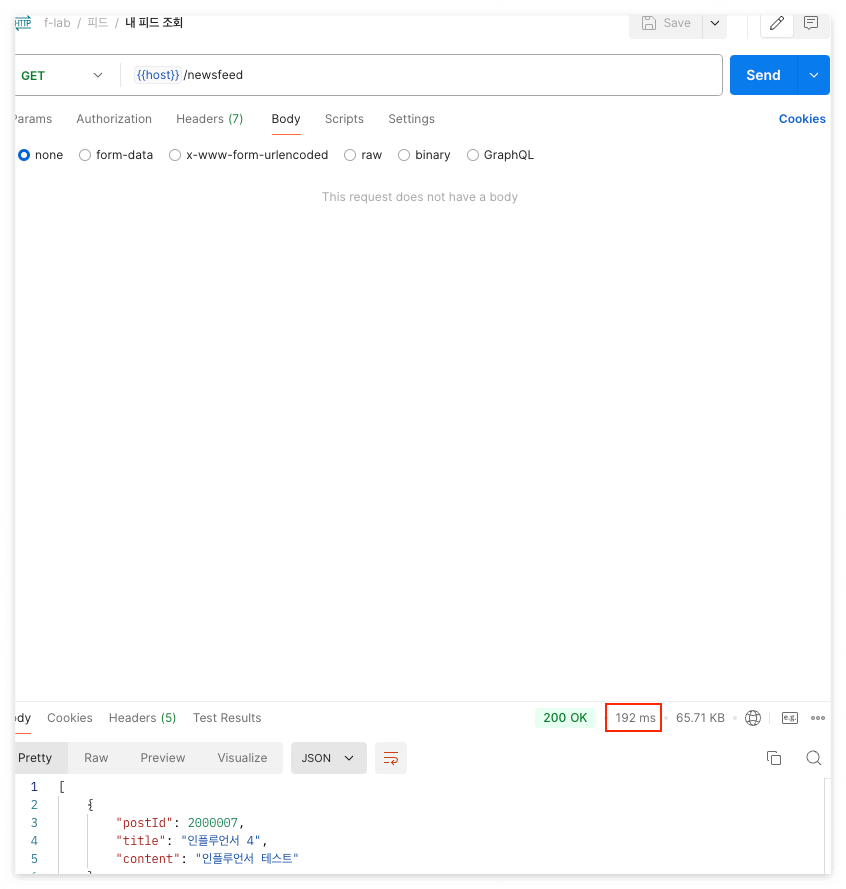
그 결과 NewsFeed 조회 시 0.2초 이내로 줄어든 것을 확인할 수 있습니다.
Q) 그렇다면 팔로잉한 사용자의 최신 게시글을 조회하려면 어떻게 해야할까요?
A) TTL을 짧은 시간으로 설정하여 최신글을 자주 보여줄 수 있지만 이 경우에도 비용이 높은 쿼리를 수행해야합니다.
Q) 비용이 높은 쿼리를 수행하지 않고 실시간으로 사용자가 최신 게시글을 조회하려면 어떤 방식을 활용해야 할까요?
A) 게시글 작성 시 나를 팔로우한 사용자의 Redis 데이터에 최신 Post ID를 추가합니다. (Fan Out)
Fan Out 방식 적용
나를 팔로우하는 사용자들의 Redis Cache를 업데이트를 진행한다면 팔로워들은 비용이 높은 쿼리를 수행하지 않고도 최신 게시글을 조회할 수 있습니다.

@Service
@RequiredArgsConstructor
public class PostService {
private static final String POST_KEY = "account:%d:posts";
private final PostJpaRepository postJpaRepository;
private final AccountRepository accountRepository;
private final FollowJpaRepository followJpaRepository;
private final RedisClient redisClient;
@Transactional
public void registerPost(RegisterPostRequest request, Long userId) {
String title = request.title();
String content = request.content();
String imageUrl = request.imageUrl();
Account account = accountRepository.findById(userId)
.orElseThrow(() -> new NotFoundAccountException(userId));
Post post = postJpaRepository.save(new Post(title, content, imageUrl, account));
fanOut(account, post);
}
private void fanOut(Account account, Post post) {
Long followerCount = followJpaRepository.countByFollowing(account);
if (followerCount < 1000) {
List<Follow> followers = followJpaRepository.findAllByFollowing(account);
for (Follow follower : followers) {
Long id = follower.getFollower().getId();
// 가장 오래된 데이터를 제거합니다.
redisClient.rightPop(POST_KEY.formatted(id));
// 최신 데이터를 저장합니다.
redisClient.leftPush(POST_KEY.formatted(id), post.getId());
}
}
}
}
이후 게시글을 올리게 된다면 팔로워들은 새로운 게시글을 빠르게 조회할 수 있습니다. :)
Learning Point
1. Redis 사용하여 Caching 으로 Performance 향상
➢ 80s → 0.2s
2. 팔로워가 많아지는 경우 Fan Out의 비용이 높을 수 있다는 점
➢ Silver Bullet은 없으니 적재적소에 기술을 사용해야한다는 점
3. Caching 을 활용할 데이터 선정 방식
➢ 정합성이 맞지 않아도 복구할 수 있는 데이터로 진행해야한다는 점
'Infrastructure' 카테고리의 다른 글
| ElasticSearch vs MySQL FullText vs MySQL Like Performance (0) | 2024.11.03 |
|---|